AI Agent 演进:从 LLM 基础到自进化多智能体系统
编辑
先说一个反常识的结论,很多人在用了 LLM 一两年之后才真正理解:模型本身,往往是 AI Agent 系统里最不重要的变量。
决定一个 Agent 系统能否可靠完成任务的,是围绕模型构建的架构——它能调用哪些工具、能访问什么记忆、用什么规划机制驱动决策、有什么安全机制防止失控。选 GPT-4o 还是 Claude 系列,在很多实际任务里的影响,远小于你的 System Prompt 设计质量和工具调用链的可靠性。
第一部分:LLM 基础——被"文字接龙"神话误导的那些年

LLM 是什么?"文字接龙"引擎
大语言模型在底层只做一件事:预测下一个 Token。给定一段文字,计算词表上的概率分布,然后采样。没有推理,没有理解,没有意图——只有在海量人类文本上训练出来的、极其复杂的模式补全。
我认为最有用的心智模型是:LLM 是一个概率性文字接龙引擎。GPT-3 生成句子时,做的事情在概念上和手机输入法的联想词非常相似——只是上下文更长、模式更复杂。"智能"的幻觉来自训练数据中模式的规模,而不是真正的推理。
这个心智模型可以直接解释为什么早期那么多 LLM 集成项目都失败了。开发者期望模型"理解"需求,但模型实际做的是找到给定输入下统计概率最高的续写。有时候这与意图吻合,经常不吻合。
五个工程上绕不开的结构性限制
无状态性:每次 API 调用都是全新开始。模型在请求之间没有任何持久记忆。你需要的上下文——对话历史、用户状态、任务进展——必须在每次调用时显式注入。无状态性让水平扩展和可重现性成为可能,但也意味着 Agent 系统里所有的记忆机制都是对这一限制的补偿。
逐 Token 生成:LLM 顺序生成输出,每次一个 Token,每个 Token 只能被之前的 Token 影响。模型无法"往前看",无法修改已生成的 Token。这造成了一个典型的失败模式:一旦走上错误的推理路径,后续每个 Token 都在强化这个错误,模型没有纠错机制。
上下文窗口限制:模型"看到"的所有文本受上下文窗口限制。GPT-3 是 2048 Token,GPT-4 是 128K,Claude 3 是 200K,Gemini 1.5 最高 100 万 Token。但即使是 100 万 Token,研究也揭示了"丢失在中间"问题——模型对超长上下文中间位置的内容注意力显著降低,开头和结尾才是高注意力区。
知识截止:训练数据有时间戳。2023 年 10 月截止训练的模型,对之后的事件一无所知,除非你显式注入。这不是一个可以"聪明提示"解决的问题,而是要求 RAG 架构的根本性约束。
无法直接执行操作:LLM 不能发送邮件、执行代码、调用 API、写入文件系统。它只能输出描述应该发生什么的文字。所有实际操作都必须由外部系统代为执行。这个鸿沟,就是 Function Call 和 Agent 架构存在的理由。
第二部分:LLM 接口规范——OpenAI API 如何成为事实标准
为什么 OpenAI API 成了 AI 世界的 HTTP
2023 年 3 月 OpenAI 发布 ChatGPT API 时,围绕"消息"和"角色"设计了一套简洁的 REST 接口。几个月内,Anthropic、Google、Mistral、Groq 等主流提供商要么直接采用同一接口规范,要么提供兼容适配器。今天,OpenAI API 格式已经是 LLM 接口的 HTTP——事实标准。
这对工程师的实际意义:LangChain、Spring AI、LiteLLM 等主流框架原生支持 OpenAI API。从 GPT-4 切换到 Claude 3 通常只需改一行配置。
核心 Request / Response 字段
{
"model": "gpt-4o",
"messages": [
{"role": "system", "content": "你是一个专业的 Java 开发助手..."},
{"role": "user", "content": "帮我解释 Spring AI 的工作原理"},
{"role": "assistant", "content": "Spring AI 是..."},
{"role": "user", "content": "和 LangChain 有什么区别?"}
],
"temperature": 0.3,
"max_tokens": 2048,
"tools": [...],
"tool_choice": "auto"
}对应的 Response:
{
"id": "chatcmpl-abc123",
"model": "gpt-4o-2024-05-13",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "Spring AI 是基于 Spring 生态的 LLM 集成框架...",
"tool_calls": null
},
"finish_reason": "stop"
}
],
"usage": {
"prompt_tokens": 120,
"completion_tokens": 350,
"total_tokens": 470
}
}三个 Agent 工程师花时间最多的字段:
system 角色:这是 Context/Harness Engineering 的核心战场。System Prompt 定义模型的身份、行为约束、输出格式和可用上下文。同一个模型因为 System Prompt 不同,可能会表现天壤之别——有时候差距比换一个更贵的模型还大。LMSYS 竞技场数据显示,同一模型不同 System Prompt 的 Elo 分差可达 5-10 分,而这个差距经常超过同级别不同模型之间的差距。
messages 数组:对无状态性的补偿机制。每次 API 调用都包含完整对话历史。你负责管理这个数组——保留几轮对话、何时压缩、何时截断。这就是 Agent 的短期记忆。
temperature:0 = 确定性输出(每次相同),2 = 高随机性。Agent 推理和代码生成用 0-0.3,创意写作用 0.7-1.0。不要对所有场景都用默认值 0.7。
Function Call:从文字到行动的桥梁
Function Call(2023 年 6 月)是对 LLM API 最重要的能力添加。它将模型从文字生成器改造成了协调器。
工作机制:你以 JSON Schema 定义工具。模型判断需要调用工具时,返回包含工具名和参数的结构化响应——而不是自由文本。你的应用程序执行实际函数,将结果返回给模型继续推理。
{
"type": "function",
"function": {
"name": "query_order_status",
"description": "查询指定订单号的物流状态",
"parameters": {
"type": "object",
"properties": {
"order_id": {"type": "string", "description": "订单编号"},
"include_timeline": {"type": "boolean", "description": "是否包含物流时间线"}
},
"required": ["order_id"]
}
}
}当模型决定调用工具时,Response 的 message 会包含 tool_calls 数组,而不是(或与)content:
{
"choices": [
{
"message": {
"role": "assistant",
"content": null,
"tool_calls": [
{
"id": "call_abc123",
"type": "function",
"function": {
"name": "query_order_status",
"arguments": "{\"order_id\": \"ORD-20260524-001\", \"include_timeline\": true}"
}
}
]
},
"finish_reason": "tool_calls"
}
]
}注意 finish_reason 是 "tool_calls"(不是 "stop"),arguments 是一个 JSON 字符串,你的代码必须自行解析。应用程序执行函数后,将结果作为 role: "tool" 消息追加回对话,再发一次请求让模型生成最终回答。
关键认知:模型不执行任何操作,它只是请求执行。 你的应用程序拥有实际的函数调用权。模型协调,外部系统执行——这个关注点分离是本文所有 Agent 系统的架构基础。
第三部分:从 Prompt 到 Agent——使用方式的演进路径
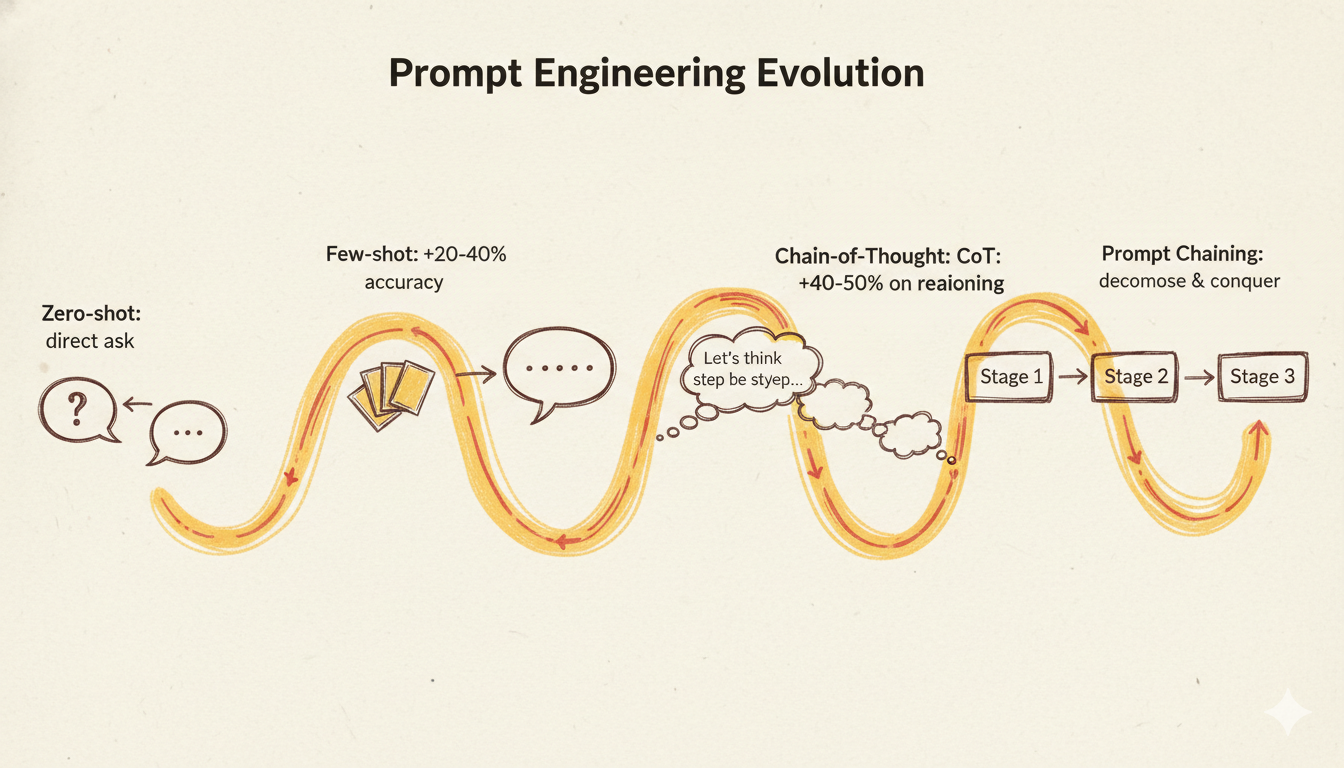
Prompt Engineering:所有架构的地基
在 RAG、Agent、MCP 出现之前,只有 Prompt。如何表达你的需求,直接决定模型能给出什么。
Zero-shot 提示:不提供示例,直接让模型完成任务。简单快速,但在需要格式一致性的任务上不可靠。
Few-shot 提示:在实际查询之前提供 2-5 个输入-输出示例。对分类、信息提取、结构化格式等任务,Few-shot 通常比 Zero-shot 准确率高 20-40%。示例充当隐式的格式规范——告诉模型"好的输出长这样"。
我的实践原则:任何需要输出格式一致性的任务——结构化数据提取、按特定风格生成代码、分类 Schema——都应该用 Few-shot。3 个示例大约 100 Token 的成本,几乎总是值得换取的一致性提升。
Chain-of-Thought:让模型"展示推理过程"
2022 年,Jason Wei 等人发现只需在 Prompt 末尾加上"让我们一步步思考",LLM 在 GSM8K 等多步骤推理 Benchmark 上的准确率提升 40-50%。这就是思维链(CoT)提示。
机制:强制模型生成中间推理步骤,利用自回归架构——每个推理步骤成为可见上下文,引导后续 Token 朝向更连贯的结论。
这对 Agent 设计至关重要:CoT 是手动的,Agent 规划是自动的,但两者本质相同。当 Agent 做出错误决策,检查它的中间推理步骤,就像调试 CoT 输出一样。
Prompt Chaining:向 Agent 流水线过渡
Prompt Chaining 的核心洞察:大多数复杂任务不应该用单次 LLM 调用解决。把任务拆成顺序流水线,每个阶段的输出是下一个阶段的输入。
以文档问答为例:
阶段一 → 从长文档中提取关键事实
阶段二 → 将提取的事实压缩为摘要
阶段三 → 基于摘要回答用户问题
为什么比单次"总结并回答"的 Prompt 更好:每个阶段任务边界清晰、可以验证中间输出、可以缓存昂贵阶段、失败可以隔离到具体步骤。
Prompt Chaining 是理解 Agent 架构的跳板:Agent 本质上是自适应的 Prompt Chain——由模型自己决定下一步,而不是开发者硬编码序列。
第四部分:RAG——解决知识问题
RAG 真正解决了什么(不是搜索加问答)
"RAG 就是搜索加问答"是对这项技术最危险的误解,它导致团队把 RAG 系统做得过于简单,然后对幻觉问题百思不解。
RAG 的架构贡献是将知识存储与语言推理解耦。模型不需要"记住"事实,只需要推理。知识存在可更新的外部存储中,模型读取检索到的上下文进行推理。
这是一个架构决策,不是检索技术。意味着:你可以更新知识库而不需要重新训练模型;每个事实声明都可以追溯到源文档;通过添加文档扩展到新领域,而不是 Fine-tuning。
生产环境中 RAG 常被忽视的局限
检索噪声:如果检索到的文档块只是部分相关或包含矛盾信息,模型会尝试从噪声上下文中综合答案——结果经常比直接用模型知识回答更差。分块策略和嵌入模型的质量与 LLM 本身同等重要。
知识更新成本:RAG 比 Fine-tuning 更新知识更灵活,但对大型文档库重新分块、重新嵌入、重新索引仍然耗时耗资源。对真正实时的数据需求,RAG 还是太慢——需要实时工具调用。
RAG 无法执行操作:这是 RAG 的能力天花板。用户说"帮我订一张去上海的机票",RAG 能检索航班信息,但无法完成预订。这就是向全 Agent 架构演进的驱动力。
检索-生成不匹配:决定检索相关性的嵌入模型,和负责生成的 LLM 是不同的模型。语义上与查询相似的文档块,不一定包含生成准确回答所需的精确信息。生产级 RAG 通常需要 Reranking(用交叉编码器对检索结果重新打分)。
第五部分:MCP——AI 工具接入的 USB 时刻
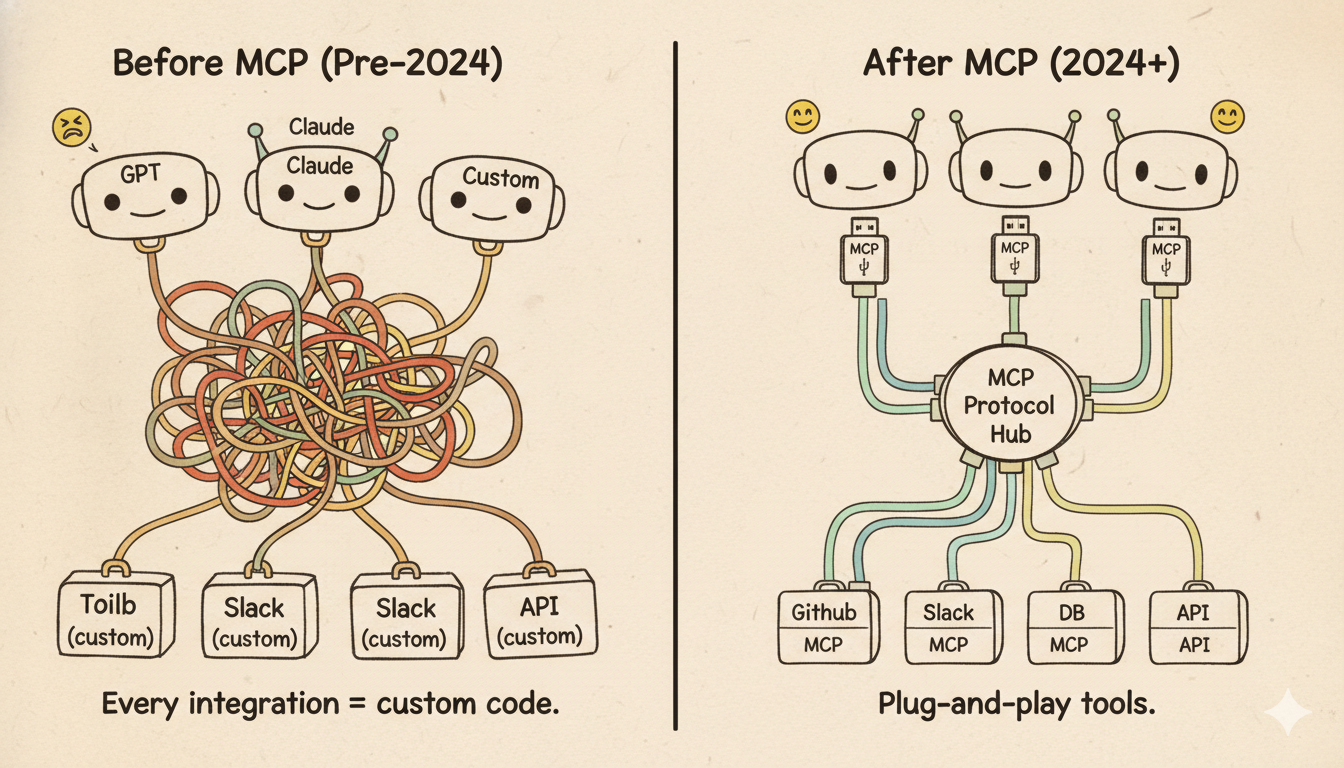
MCP 解决的问题:USB 发明之前的世界
MCP 出现之前,每个 LLM 应用都在重复造轮子:集成 GitHub 写一套适配器,集成钉钉再写一套,集成数据库再写一套。更麻烦的是,从 GPT-4 切换到通义千问,所有工具集成都要重写。
这就是 USB 发明之前的世界——每个外设都有专属接口,没有标准。
2024 年 11 月,Anthropic 发布 MCP(Model Context Protocol)。 定义了 LLM 以统一方式访问工具、文件系统、数据库、API 的标准协议。三个核心角色:
Host:运行 LLM 的应用(Claude Desktop、Cursor、你的自定义应用)
Client:嵌在 Host 中的 MCP 协议客户端
Server:通过协议暴露能力的服务(GitHub MCP Server、文件系统 Server 等)
MCP 发布三个月内获得 200+ integrations。更深层的意义:工具应该是模型无关的,通过协议暴露能力,而不是硬编码在应用里——这是从"每个应用自己集成工具"到"工具作为基础设施"的范式转变。
MCP vs Function Call:不是竞争,是不同层次
Function Call 是机制,MCP 是生态标准。 MCP Server 通过标准协议暴露工具,底层 LLM 调用 MCP 工具时仍然使用 Function Call 机制。MCP 标准化的是工具如何被定义、发现和连接。
MCP 的真实局限
安全边界不成熟:具有文件系统或 Shell 访问权限的 MCP Server 是重大攻击面。Prompt 注入到工具返回结果中可以劫持 Agent 行为。
协议仍在快速演进:版本兼容性问题在大规模企业部署中会带来升级摩擦。
无内置认证:MCP 不标准化鉴权,每个 Server 自己实现,在企业级集成中造成额外复杂性。
第六部分:Agent 的出现——四要素缺一不可
什么才是真正的 Agent
Planning 是 Agent 与单次 LLM 调用的分水岭。Agent 能把"写并测试一个数据处理脚本"分解成子任务,跨多轮追踪进度,当中间结果改变情况时调整计划。
Tool Use 是 Agent 与聊天机器人的分水岭。Agent 能执行真实操作:搜索网页、执行代码、读写文件、调用 API。模型协调,外部系统执行。
Memory 补偿 LLM 的无状态性。短期记忆存在消息列表里(上下文内)。长期记忆外化到数据库。两者都需要主动管理——你决定保留什么、压缩什么、检索什么。
Observation 闭合反馈循环。执行操作后,Agent 接收结果,通过 LLM 处理,决定下一步行动。这个循环使自我纠正成为可能——这是 Agent 区别于自动化流水线的定义性能力。
去掉这四个组件中的任何一个,你就不再有 Agent,只有一个有限自动化能力的 LLM 应用。
第七部分:ReAct——最原始的 Agent 循环
Observation → Thought → Action
ReAct 论文(Yao 等,Princeton/Google,2022)形式化了最基础的 Agent 范式。模型不是直接生成最终答案,而是交替进行:
Thought:推理当前状态和下一步应该做什么
Action:请求执行特定工具调用
Observation:接收工具执行结果
循环持续直到模型判断任务完成或达到步骤上限。
ReAct 的精妙之处:通过使推理可见(每个 Thought 步骤作为可见文本生成),中间推理引导后续步骤,完整推理链也可用于调试。当 Agent 做出错误决策时,你有完整的每步决策记录。
ReAct 在知识密集型基准如 HotpotQA 和 FEVER 上,比纯 CoT 方法准确率高 20-30%,因为 CoT 无法在模型知识不足时访问外部信息。
ReAct Agent 伪代码
def react_agent(goal: str, tools: dict, max_steps: int = 20) -> str:
messages = [
{"role": "system", "content": f"""你是一个 AI Agent。通过以下方式完成目标:
1. Thought:推理下一步应该做什么
2. Action:从 {list(tools.keys())} 中调用一个工具
3. Observation:读取结果,然后继续
完成时回复:最终答案:<答案>"""},
{"role": "user", "content": f"目标:{goal}"}
]
for step in range(max_steps):
response = llm_call(messages)
if "最终答案:" in response:
return response.split("最终答案:")[1].strip()
thought, action, action_input = parse_react_output(response)
# 执行工具(模型请求,应用程序执行)
observation = tools[action](action_input) if action in tools \
else f"错误:未知工具 '{action}'"
# 追加到上下文记忆
messages.append({"role": "assistant", "content": response})
messages.append({"role": "user", "content": f"Observation: {observation}"})
return "达到最大步骤数未完成"从这段代码可以看出:基础 ReAct Agent 的"记忆"就是不断增长的消息列表。每次工具调用结果都追加到上下文。任务越长,上下文越大,最终触及窗口限制。这正是 Context 压缩和长期记忆对复杂 Agent 不可或缺的原因。
第八部分:工作流 Agent——用结构换可靠性
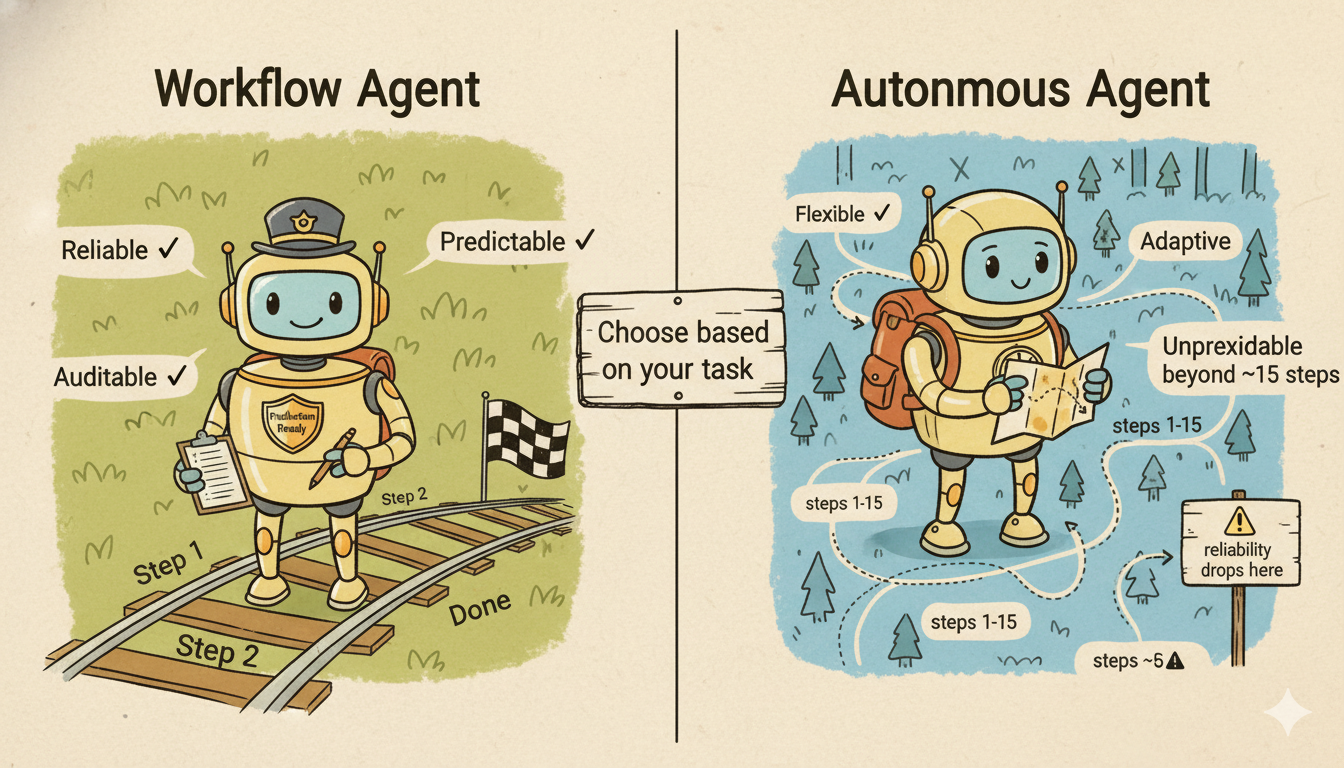
"让模型自己决定"并不总是好主意
2023 年 AutoGPT 实验给整个行业上了一节昂贵的课。尝试对"建一个网站"这样的开放目标给予完全自主权:结果是无限循环、幻觉级联、API 成本失控。完全自主放大了失败模式,而不是提升了能力。
工作流 Agent 是工程上的回应:开发者定义的工作流指定高层任务序列,LLM 在每个有边界的步骤内部做决策,而不是自主规划整个序列。
权衡是明确的:用通用性换可靠性。工作流 Agent 无法处理预定义结构之外的任务类型,但在其结构范围内,可靠性显著高于完全自主 Agent。
适合工作流 Agent 的场景:面向用户的生产应用(可靠性不可妥协)、有合规或审计要求的场景、高成本操作(不能承受失控执行)、任务步骤边界清晰且稳定。
工作流 Agent 不够用的场景:路径未知的开放式研究任务、需要真正自适应的复杂多领域任务。
第九部分:自主 Agent——复杂规划与长程任务
能力边界与可靠性天花板
自主 Agent 接收目标,自己制定完整计划。无需开发者预定义工作流。Agent 分解任务、选择工具、执行步骤、根据中间结果调整——全程无人干预。
这听起来是我们一直期待的终点。实际上,在大约 15 步以上,它是一个可靠性工程噩梦。
研究和生产数据一致显示:Agent 任务成功率随步骤数增加急剧下降。 能可靠完成 5 步任务的 Agent,在 20 步任务上成功率可能只有 30-40%。错误会级联——第 3 步的错误假设,会让第 4-20 步在逻辑上前后矛盾,而 Agent 往往无法自我察觉。
Manus:2025 年自主 Agent 的现实案例
Manus(2025 年)成为第一个被广泛讨论的真实场景自主 Agent:自主浏览网页、执行代码、管理文件、填写表单、编写并运行脚本——全部基于自然语言目标。
值得关注的是它的计算机使用范式:Agent 控制真实的浏览器和桌面环境,而不是调用结构化 API。这让它无需自定义集成就能访问任何 Web 界面。
客观评价:Manus 在研究导向任务上表现出真实进步——"研究这个主题并写报告"、"搭建这个开发环境"。在需要精确多步骤协调的陌生环境任务上,它失败了,有时代价不小。15-20 步的可靠性天花板依然成立。
给生产系统的教训:自主 Agent 在探索性、研究导向的任务上价值最大,在那里不完美结果是可接受的。对需要精确执行的场景,加入检查点、人工确认关卡和有熔断机制的重试逻辑。
第十部分:Multi-Agent——多角色协作
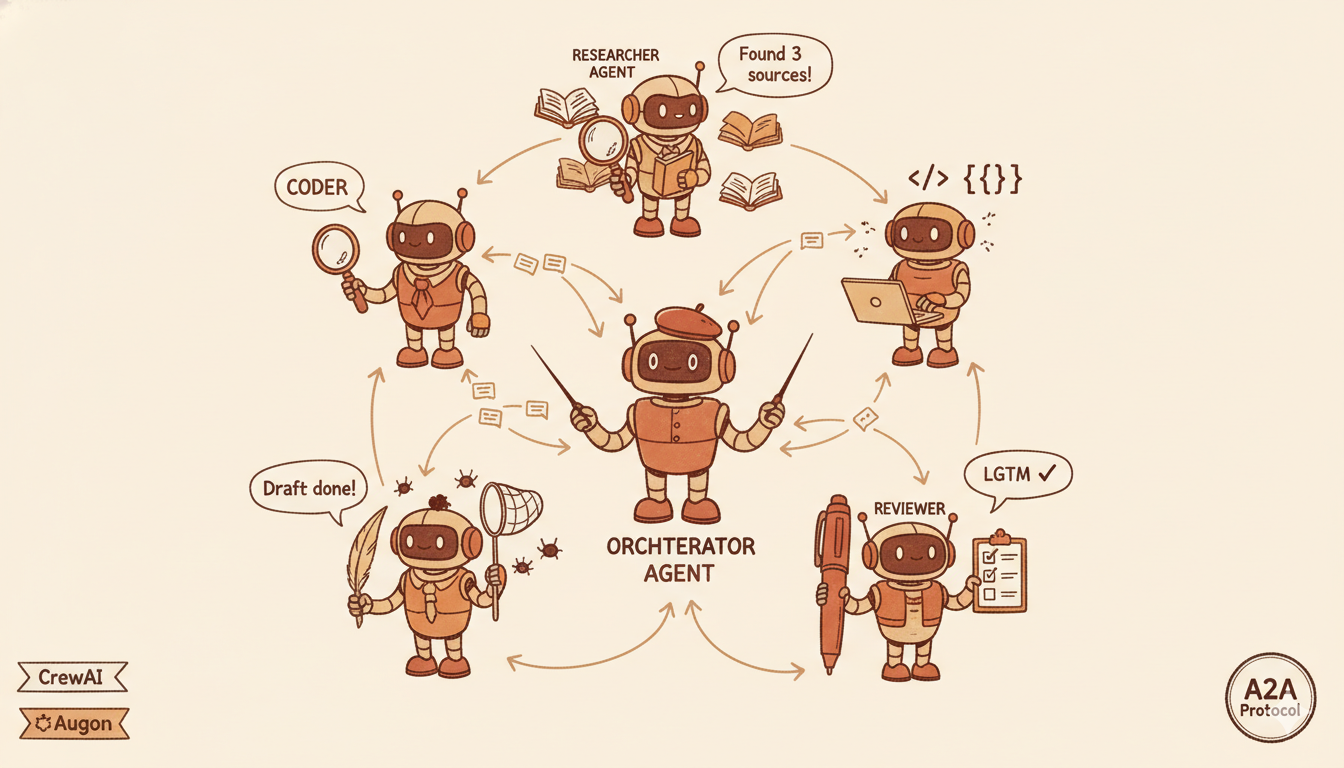
为什么单一全能 Agent 通常不是正确架构
复杂任务不是由全能选手解决的,而是由专家协作解决的。软件开发任务不需要一个"什么都会"的模型,需要规划者、开发者、代码审查者和测试者各司其职,每个角色都针对自己的领域做了优化。
Multi-Agent 架构的三个具体收益:
专业化:每个 Agent 的 System Prompt 和可用工具都针对单一角色,提升质量
并行化:独立子任务并发执行,缩短整体耗时
错误隔离:单个 Agent 的失败不会级联到整个系统
CrewAI 和 AutoGen:两种主流模式
CrewAI:角色驱动的 Crew 模式,定义 Agent 的角色、目标和背景,配置顺序或层级工作流。偏好约定、原型开发快。
AutoGen(微软):对话式协调,Agent 通过结构化消息传递通信,支持更复杂的拓扑——Agent 可以生成子 Agent、协商、动态协作。灵活性更高,配置更复杂。
A2A 协议:标准化 Agent 间通信
2025 年 Google 发布 A2A(Agent-to-Agent)协议,填补了 MCP 留下的空白:MCP 标准化了 Agent 如何连接工具,但没有标准化 Agent 之间如何通信。
A2A 定义:
Agent Cards:Agent 能力的自描述声明,用于 Agent 相互发现
任务协议:委派和追踪跨 Agent 任务的标准消息格式
流式支持:长时间跨 Agent 操作的实时部分结果
A2A 遵循 MCP 的路线:在生态系统因不兼容实现而分裂之前建立协议标准。对于今天构建 Multi-Agent 系统的团队,值得密切关注 A2A 的采用进展。
第十一部分:自进化 Agent——关闭学习循环
所有固定 Agent 都会遇到的天花板
到目前为止讨论的所有 Agent 架构都有同一个限制:其能力被构建时设计的内容所限定。工具固定,推理模式固定,System Prompt 固定。在约束内可以很聪明,但无法改进自身的约束。
自进化 Agent 试图关闭这个循环:利用 Agent 自身的执行经验改善未来表现。这是 2025-2026 年 Agent 研究的前沿。
Self-Reflection 与经验回放
Self-Reflection(Reflexion 论文,Shinn 等,2023):任务失败后,Agent 反思哪里出了问题,生成失败的口头分析,并将这个"教训"存储为未来尝试的上下文。这不是梯度下降意义上的学习——而是结构化反思,偏置未来推理向更正确的方向。
Reflexion 论文显示,经过 3-5 轮反思循环,Agent 在多步骤顺序决策任务上的成功率从约 30% 提升到约 60%。机制:口头反思创造了关于失败模式的显式上下文,影响后续推理链。
经验回放将这扩展到跨会话持久化:不只在会话内反思,而是将结构化执行经验存储到长期记忆,为新任务检索相关历史经验。
Memory 架构:短期 vs 长期
Context 压缩是管理短期到长期记忆过渡的工程方法:
滑动窗口:只保留最近 N 条消息
摘要压缩:定期将旧上下文压缩为摘要
选择性保留:用 LLM 判断哪些 Observation 值得保留
分层压缩:原始事件 → 摘要 → 关键事实
工具演进:从 Function Call 到 CLI 和脚本
从 Function Call 到 CLI 到计算机使用,是能力和风险面同步扩展的过程。具有 Shell 访问权限的 Agent 几乎可以做开发者能做的任何事——包括在 Prompt 注入成功的情况下删除生产数据或泄露敏感信息。
第十二部分:Agent 安全与治理
能力与风险的不对称性
早期 LLM 应用的影响半径有限:聊天机器人给出错误答案,代价是一个困惑的用户。拥有文件系统访问权、API Key 和 Shell 执行能力的 Agent 的影响半径完全不同:它可以删除文件、提交恶意代码、发送邮件、调用 API、创建云资源。能力扩展与安全研究之间的差距,是当前 Agent 时代最大的工程挑战。
沙箱执行
第一道防线:永远不要让 Agent 在没有隔离的宿主环境中执行代码。
生产 Agent 系统使用:
容器隔离:代码在短暂的 Docker 容器中执行。每个任务获得一个全新环境。任何破坏都被隔离,任务结束容器销毁。
资源限制:执行时间(30-120 秒)和资源消耗(CPU、内存、网络)的硬上限,防止失控进程。
网络限制:对不需要外部连接的代码执行任务,限制或过滤沙箱容器的网络访问。
权衡:沙箱增加延迟(容器启动:500ms-2 秒)并限制工具访问。对于任何处理不可信或用户提供输入的 Agent,沙箱是不可协商的。
权限控制
最小权限原则应用于 Agent:只授予当前任务所需的权限,不多一分。
范围化 API 密钥:不要给 Agent 完整的 GitHub Token,生成仅限特定仓库和操作的细粒度 Token
写前确认门:对任何破坏性操作(删除、部署、推送到 main),要求明确的人类确认
操作白名单:定义每个 Agent 角色允许的工具和操作范围
预算上限:对每个会话设置最大 Token 消费和 API 调用上限
最难解决的问题:Prompt 注入。嵌入在工具返回结果中的恶意指令(Agent 读取的网页、处理的文件)可以劫持 Agent 行为,潜在地提升权限或泄露数据。目前没有通用解决方案——纵深防御是当前最佳实践。
可观测性:无法治理看不见的东西
生产 Agent 系统的最低遥测要求:
追踪日志:每个推理步骤、工具调用和 Observation,含时间戳和 Token 计数
成本追踪:按任务、按 Agent、按用户的 Token 消耗和费用——附硬性预算上限
异常检测:当 Token 数、延迟或单任务成本超出阈值时告警
人工审查队列:将低置信度或高风险决策路由到人工审查
我在生产中见过的一个具体错误:上线没有单任务成本上限的 Agent。一个卡在重试循环中的失控 Agent 会话,在任何人注意到之前就能累积 3000+ 元的 API 费用。始终在应用层(而不只是模型参数层)设置每任务的最大 Token 预算。
第十三部分:AI 开发框架
LangChain:开疆拓土的先驱
LangChain(Python/JS,2022 年)向社区证明了 LLM 原语——工具、链、Agent、记忆、RAG——可以被抽象为可组合的组件。它成为 GitHub 历史上增长最快的项目之一。
LangGraph(LangChain 的工作流扩展)增加了基于图的工作流编排,让有状态的多步骤工作流更易于构建和推理。
客观评价:LangChain 的 API 经历了多次重大重写——快速迭代的标志,也是升级摩擦的来源。对于启动新项目的团队,评估抽象层带来的开销是否值得,对比直接使用较低层次的库。
适合使用 LangChain 的场景:Python 优先的团队、快速原型开发、需要最广泛的集成生态、想用 LangSmith 做内置可观测性。
Spring AI 与 Spring AI Alibaba:企业 Java 的选择
Spring AI(2024 年)将 LLM 集成带入 Java/Spring 生态,采用熟悉的 Spring 模式:@Bean 配置、自动装配、依赖注入。通过统一 API 支持 OpenAI、Anthropic、Azure OpenAI 等主流提供商。
Spring AI Alibaba 在 Spring AI 基础上提供对阿里云服务的一流集成:通义千问模型、阿里云百炼平台,以及国内主流 LLM 提供商的支持。对于使用阿里云基础设施或面向中文语言任务的团队,Spring AI Alibaba 是明确的首选。
@Configuration
public class AgentConfig {
@Bean
public ChatClient chatClient(ChatClient.Builder builder) {
return builder
.defaultSystem("你是一个专业的技术助手,擅长 Java 开发...")
.defaultTools(new QueryTool(), new CodeAnalysisTool())
.build();
}
}
// 发起 Agent 调用
String response = chatClient.prompt()
.user("帮我分析这段代码的性能瓶颈:" + code)
.call()
.content();适合使用 Spring AI 的场景:Java/Spring 后端团队、企业级合规要求、现有 Spring 基础设施、阿里云部署(Spring AI Alibaba)。
AgentScope:阿里巴巴的 Multi-Agent 框架
AgentScope(阿里巴巴,2024 年)是专为多个专业 Agent 协调复杂任务场景优化的开源 Multi-Agent 框架。
核心特性:
消息传递架构:Agent 通过结构化消息通信,无共享可变状态
容错机制:内置单 Agent 失败的重试和恢复
分布式部署:Agent 可运行在不同主机上,通过网络通信
监控看板:Agent 对话流程和消息交换的可视化观测
AgentScope 特别适合:自动化代码审查流水线、数据管道编排、研究工作流,以及任何需要可靠 Multi-Agent 协调和可观测性的场景。
适合使用 AgentScope 的场景:构建生产级 Multi-Agent 系统的 Python 团队、需要容错和分布式部署、想要原生监控。
决策框架:为你的任务选择正确的架构
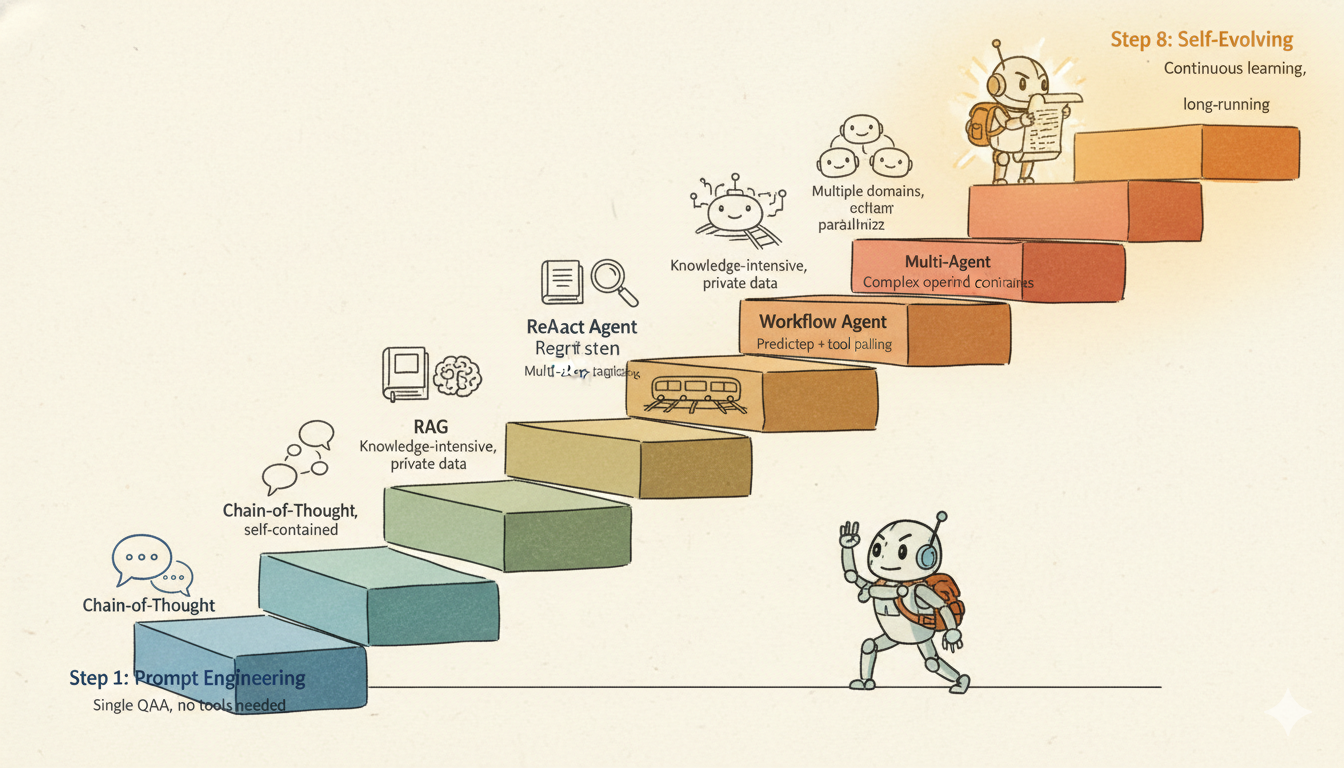
梳理完这条完整演进路径,给出我的实践决策框架:
不可协商的安全规则:任何有执行能力的 Agent 上线前,必须有:
代码执行的沙箱隔离
外部 API 的权限范围化
单任务成本/Token 预算
每个操作的追踪日志。能力没有可观测性,就是不可治理。
- 0
- 0
-
赞助
 微信
微信
-
分享